
The random forest algorithm explained (with Python code you can use in interviews)
(Read this if you use XGBoost for everything)

5 years ago, I f*** up a data science interview because of a random forest algorithm question.
And it’s really not because I didn’t know what it was because I knew it was an ensemble method in machine learning and I could recite “it combines multiple decision trees to reduce variance.”
But the interviewer didn’t ask me to define a random forest.
She asked me to explain what happens when you add more trees.
Then she asked what I’d do if the model was overfitting.
Then: “How would you know if a feature actually mattered?”
I froze. I had memorized the what and skipped the why. Rookie mistake…
That gap between being able to define a model and being able to reason about it is what costs people jobs.
So I want to help you avoid making the same mistake I made (and yes you will get your hands dirty and run some code)…
How does random forest work?
Start here: a single decision tree is great at memorizing your training data and terrible at generalizing to new data. That’s overfitting.
You’ve probably run into it: 98% accuracy on training, 67% on test. The model learned the noise, not the signal.
The random forest algorithm fixes this with a simple idea: if one tree is wrong, maybe 500 independent trees aren’t all wrong at the same time.
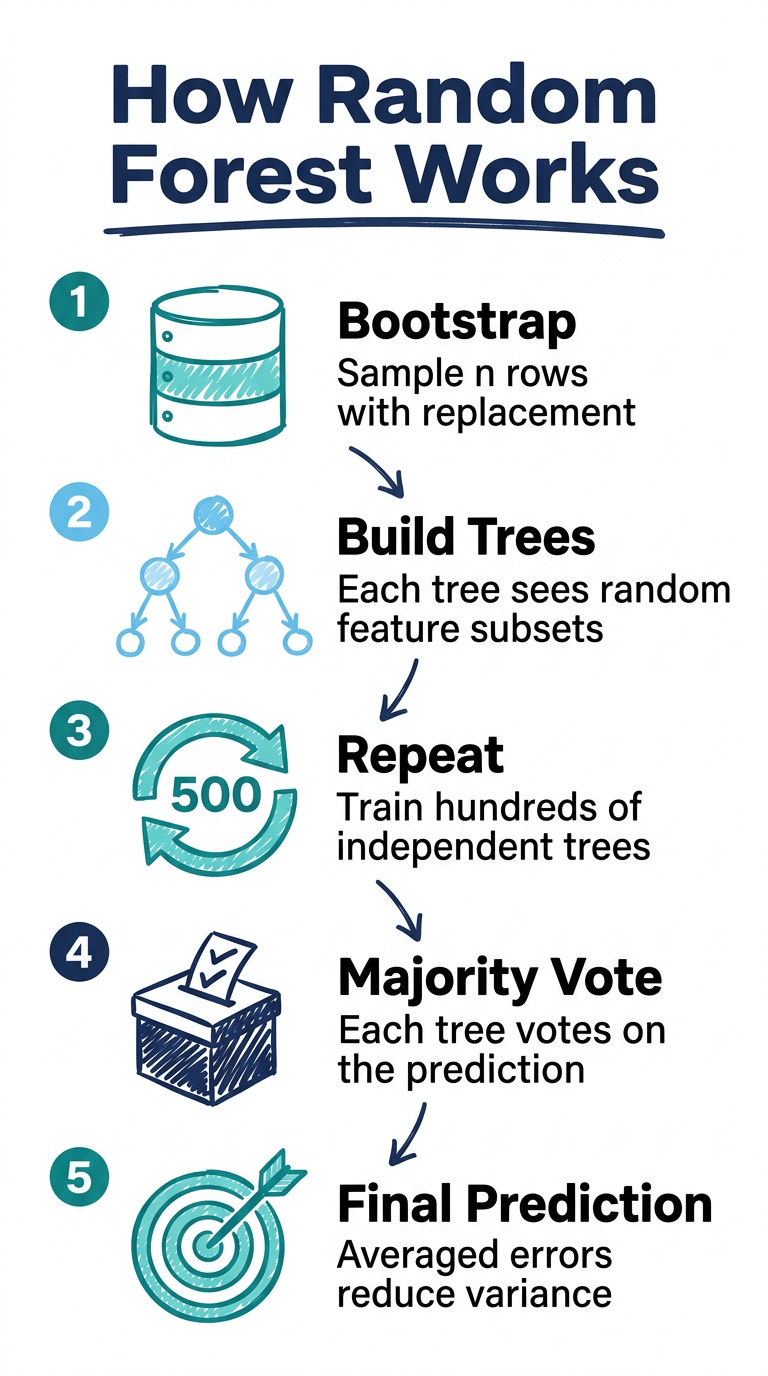
Here’s the mechanics of how random forest works:
Take your original dataset of n rows
Sample n rows from it with replacement (this is called bootstrapping — some rows appear twice, some don’t appear at all)
Build a decision tree on that sample, but at each split, only consider a random subset of features — not all of them
Repeat 500 times (or however many trees you configure)
To make a prediction, run the data through all 500 trees and take a majority vote (for classification) or average (for regression)
Two things happen here that matter.
First, each tree trains on different data (bootstrapping), so they make different errors.
Second, each tree considers different features at each split, so they’re not all just finding the same obvious pattern.
These two sources of randomness are what make the ensemble smarter than any individual tree.
This is the insight to have ready: random forest reduces variance by averaging across models that disagree with each other.

Build a random forest in Python with scikit-learn
This is the full working version. Paste it into a notebook and run it:
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
rf = RandomForestClassifier(
n_estimators=100,
max_depth=None,
random_state=42
)
rf.fit(X_train, y_train)
print(classification_report(y_test, rf.predict(X_test)))
You’ll get precision and recall both above 95%. Now you have a working scikit-learn random forest model. The next part is understanding it well enough to talk about it.
The three random forest hyperparameters that actually matter
Most tutorials list every parameter. Here are the three you need to understand if you’re preparing for an interview or building a first portfolio project — and what to say about each one:
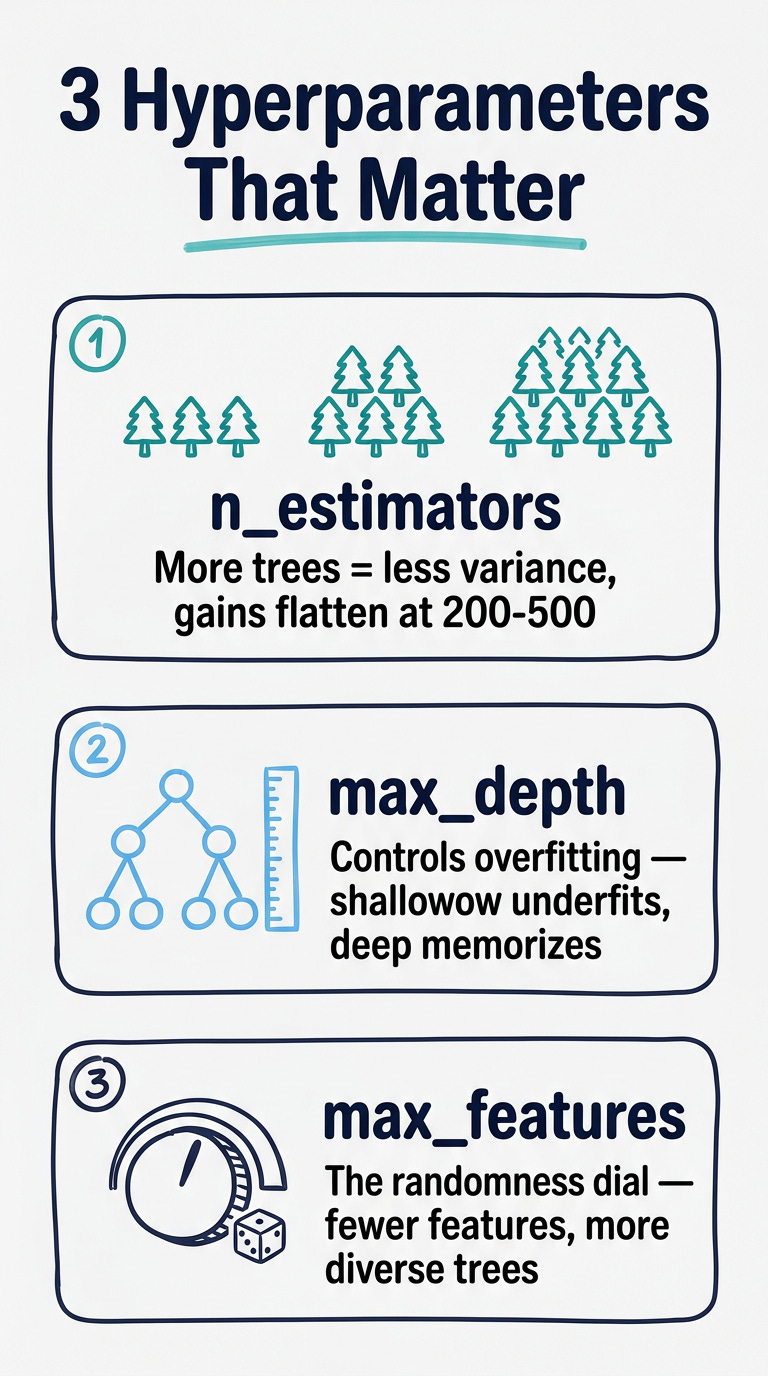
n_estimators (number of trees)
More trees = better performance, up to a point.
After roughly 200–500 trees, the accuracy gain flattens while training time keeps growing. Start with 100, increase if you have the compute budget.
What to say in an interview:
“I treat n_estimators as a compute-accuracy trade-off. I start at 100, check if performance is still improving with cross-validation, and stop adding trees when the gain is marginal.”
max_depth (how deep each tree grows)
Shallow trees = high bias (underfit). Deep trees = high variance (overfit). The random forest algorithm handles overfitting better than a single tree because of averaging, but max_depth is still a useful regularization lever.
What to say in an interview:
“I often let trees grow fully by default, then tune max_depth if I see the model is memorizing noise — I’d check by comparing train vs. test accuracy.”
max_features (features considered at each split)
This is the randomness dial. Lower = more diverse trees = more variance reduction, but also less accurate individual trees. The scikit-learn default of sqrt(n_features) works well for classification.
What to say in an interview:
“Reducing max_features increases the randomness between trees, which helps with variance. If I’m working with highly correlated features, I’ll reduce it further to force the model to find different splits.”

Random forest feature importance: the thing interviewers always ask about
After you train a random forest in Python, you get this for free:
import matplotlib.pyplot as plt
import numpy as np
importances = rf.feature_importances_
indices = np.argsort(importances)[::-1]
feature_names = X.columns
plt.figure(figsize=(10, 5))
plt.bar(range(10), importances[indices[:10]])
plt.xticks(range(10), [feature_names[i] for i in indices[:10]], rotation=45, ha='right')
plt.title("Top 10 Feature Importances — Random Forest")
plt.tight_layout()
plt.show()
Random forest feature importance in scikit-learn measures how much each feature reduces impurity (Gini impurity or entropy) across all the splits in all the trees.
High importance = the model relied on this feature a lot to make decisions.
What to say in an interview:
“Feature importance gives me a rough signal for which variables the random forest algorithm relied on most — useful for simplifying the feature set or explaining predictions to stakeholders. That said, it can be misleading with highly correlated features, where importance gets split between them. For a more reliable estimate, I’d use permutation importance instead.”
That last line — the caveat about correlated features — is the kind of detail that separates candidates who’ve actually used the model from those who’ve just read about it.
When to use the random forest algorithm (and when to skip it)
Use tree-based models ( including random forests) as your default for:
tabular data with mixed feature types,
when feature importance matters for stakeholder explanation, or
when you need a strong baseline without heavy preprocessing.
It rarely requires much data cleaning to get a solid first result.
Skip it if:
prediction speed at inference is a constraint,
if your data is sparse high-dimensional text, or
if your dataset is large enough to need distributed compute.

What to say in an interview:
“My default for tabular data is to start with random forest as a strong baseline. If I need better performance I’ll move to XGBoost or LightGBM. If I need explainability for a business audience, I’ll consider a shallower model or supplement with SHAP values.”

One thing to add to your data science portfolio
If you’re building a portfolio project with the random forest algorithm, don’t stop at accuracy.
Add this section to your README:
What the model relies on: The top 3 features by importance, and why that makes sense (or doesn’t) given the domain.
Where it breaks down: The cases it misclassifies most often — and what they have in common.
What I’d try next: Permutation importance to validate feature rankings, and XGBoost to see if boosting adds meaningful accuracy.
That three-paragraph add-on turns a notebook into a data science story. It signals to any hiring manager reading it: this person understands what they built.
One issue, one model, everything you need to talk about it with confidence.
Next week: how to actually evaluate a classification model beyond accuracy.
Keep building,
Resources:
scikit-learn: RandomForestClassifier — official docs with all parameters
Breast Cancer dataset (sklearn) — clean binary classification dataset, good for practice
StatQuest: Random Forests — best visual explanation of bootstrapping and bagging
SHAP values explained — for when feature importance needs to be more precise